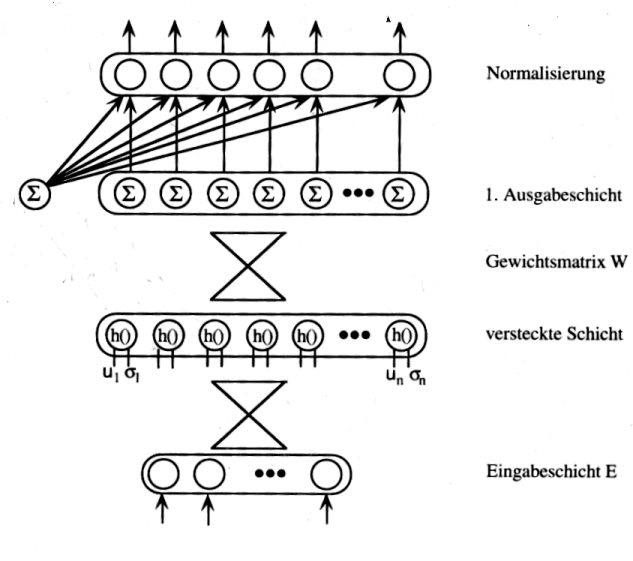
Die Ausgabe wird dann normiert, indem folgendes berechnet wird :
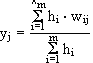
Das Training
Die Wahl der Zentren (Stützstellen)
Die Stützstellen stellen die Punkte dar, durch die die zu approximierende Funktion verlaufen sollte. Dazu könnte jeder Trainingsvektor eine Stützstelle bestimmen. Jedoch können hier statistische Ausreißer (z.B. Meßfehler) oder große Datenmengen zu Problemen führen. Daher ist man daran interessiert, das verfügbare Datenmaterial zu komprimieren. Dazu werden Cluster gebildet, in denen mehrere Trainingsvektoren zusammengefaßt werden.
ein einfacher Clusteralgorithmus
Der erste Vektor repräsentiert die erste Klasse. Solange die nachfolgenden Vektoren einen Abstand haben, der gering genug ist, werden die Vektoren in diese Klasse eingeordnet. Ist der Abstand zu groß, bildet dieser Vektor den Repräsentanten für die nächste Klasse. Ein Problem hierbei ist, daß die Reihenfolge der Vektoren Einfluß auf die Klassenbildung hat :
Beispiel : Der maximale Abstand sei 2 und die 'Vektoren' lauten 1 2 3 5. Dann führt die Reihenfolge (1,2,3,5 ) zu den Clustern { (1,2,3) , (5) } ; jedoch führt die Reihenfolge ( 3,1,2,5) zu dem einzigen Cluster (1,2,3,5) .
ein iteratives Clusterverfahren
Für den Algorithmus wird die Anzahl der Cluster bei der Initialisierung festgelegt. Dort wird auch jedem Cluster ein Referenzvektor zugewiesen. Nun wird ein Vektor aus der Datenmenge ausgewählt und der ähnlichste Cluster bestimmt. Der Referenzvektor dieses Clusters wird in Richtung des Datenvektors gezogen. Das Verfahren terminiert, wenn alle Referenzvektoren stabil bleiben. Werden solche Clusteralgorithmen verwendet, muß bei der Ausgabe noch die Anzahl der Vektoren im Cluster berücksichtigt werden. Dies führt zur folgenden Formel :
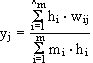
Die Streuung
Hier ist darauf zu achten, daß durch die Kombination der Stützstellen mit der Streuung der Musterraum vollständig abgedeckt wird. Paktisch kann das so aussehen, daß man um die Streuung für eine Stützstelle zu bestimmen, zunächst aus den k nächsten Nachbarn einen gemittelten Vektor bestimmt. Aus dem Abstand dieses Vektors zur Stützstelle kann man dann die Streuung ableiten.
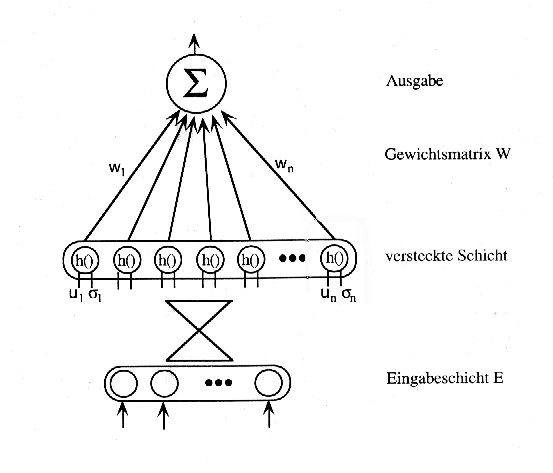
Training der Gewichtsmatrix W
Sind die Stützstellen und die Streuungsparameter festgelegt, muß das Netz noch auf die entsprechende Ausgabe hin trainiert werden. Dazu wird ein Gradientenabstiegsverfahren (Deltaregel) eingesetzt, um die Gewichtsmatrix W zu trainieren. Dazu wird zunächst die Aktivierung der Neurone in der versteckten Schicht berechnet. Dieses wird dann wie die Eingabe des einstufigen Netzes darüber behandelt.
Um eine Funktion zu approximieren, muß allerdings kein iteratives Lernverfahren angewendet werden. Da die Ausgabe der versteckten Neuronen bei einer bestimmten Eingabe berechnet werden kann, muß die Gewichtsmatrix W noch so berechnet werden, daß das Netz die gewünschte Ausgabe liefert. Sieht man sich die zu erfüllenden Gleichungen an, stellt man fest, daß ein lineares Gleichungssystem zu lösen ist, um die Gewichte entsprechend einzustellen. Daher können die Gewichte durch ein geeignetes Verfahren zur Lösung von linearen Gleichungssystemen eingesetzt werden.