CasCor-netze versuchen dieses Problem zu lösen. Im Extremfall wird hier nur ein einziges Neuron trainiert. Dieses nimmt in Richtung des Fehlersignals eine maximale Reduzierung vor. Durch das Einfügen von Neuronen in der versteckten Schicht entstehen kaskadenartige Strukturen.
Aufbau und Funktion
Ein CC-Netz ist ein FF-Netz 2.Ordnung. Es besteht aus einer Menge von Eingabeneuronen und einer Menge von Ausgabeneuronen. Im Laufe des Lernverfahren kommen noch versteckte Neuronen hinzu. Jedes Eingabeneuron ist mit jedem Ausgabeneuron direkt verbunden. Innerhalb eines Neurons wird eine sigmoide Aktivierungsfunktion auf die gewichtete Summe der Eingabe angewendet.
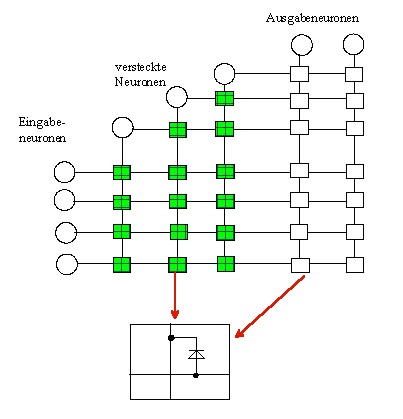
Das Lernen
Zu Beginn des Verfahrens befinden sich keine Neuronen in der versteckten Schicht. Durch ein beliebiges Gradientenabstiegsverfahren werden die Gewichte so eingestellt, daß der Fehler auf der Trainingsmenge minimal wird. Wenn dieser Fehler nun ausreichend klein ist, terminiert das Verfahren. Wenn nicht, wird ein Neuron zur versteckten Schicht hinzugefügt. Nun wird versucht, dieses Neuron so einzustellen, daß es sich stark auf das Fehlersignal konzentriert. Dieses enthält als Eingabe die Ausgaben der Eingabeneuronen und von evtl. schon vorhandenen versteckten Neuronen. Es werden noch keine Verbindungen zu den Ausgabeneuronen hergestellt. Es wird nun versucht, die Eingangsgewichte des neuen Neurons so einzustellen, daß sich das neu eingefügte Neuron so gut es geht auf das noch vorhandene Fehlersignal konzentriert. Formal wird versucht, die aufsummierten Beträge Si der Korrelation zwischen der Ausgabe oi des neuen Neurons i mit dem Fehler dk aller Ausgabeneurone zu maximieren :
Um Si zu manipulieren (zu maximieren) muß eine Abhängigkeit zu den freien Gewichten hergestellt werden. Die Herleitung der partiellen Ableitung
Auf Basis dieser Formel wird nun die Gewichtänderung von allen Gewichten zu dem neuen Neuron durchgeführt. Da dadurch Si maximal wird, konzentriert sich dieses Neuron nun speziell auf den Restfehler. Nach dem Einfügen des neuen Neurons (mit den entsprechenden Eingangsgewichten), werden nun auch die Verbindungen zu den Ausgabeneuronen hergestellt. Das Netz wird nun neu trainiert, wobei allerdings nur die Gewichte der Verbindungen zu den Ausgabeneuronen variabel sind. Dieser Vorgang des Einfügens (incl. Gewichtsberechnung für das neue Neuron) und Neutrainieren des Netzes wird solange wiederholt, bis das Netz eine ausreichende Reproduktionsleitungs aufweist.